

今日,科技界迎来了一场关于开源智能的里程碑式变革。全新的 Gemma 4 系列模型正式亮相,这不仅是参数规模的迭代,更是其迄今为止最强大的开源模型家族。专为高级推理与智能代理(Agentic)工作流量身打造,Gemma 4 在“单位参数智能密度”上实现了前所未有的突破,标志着开源模型正从简单的对话工具向复杂的逻辑执行者转型。
这一技术跨越建立在极其庞大的社区基石之上。自第一代 Gemma 发布以来,开发者下载量已突破 4 亿次,构建了一个拥有超过 10 万个变体的繁荣“Gemma 生态圈”。通过深度洞察全球创新者对突破 AI 边界的迫切需求,Gemma 4 带着更强大的推理能力应运而生,并继续沿用 Apache 2.0 许可协议,确保最前沿的 AI 能力能够以极低的门槛触达全球开发者。
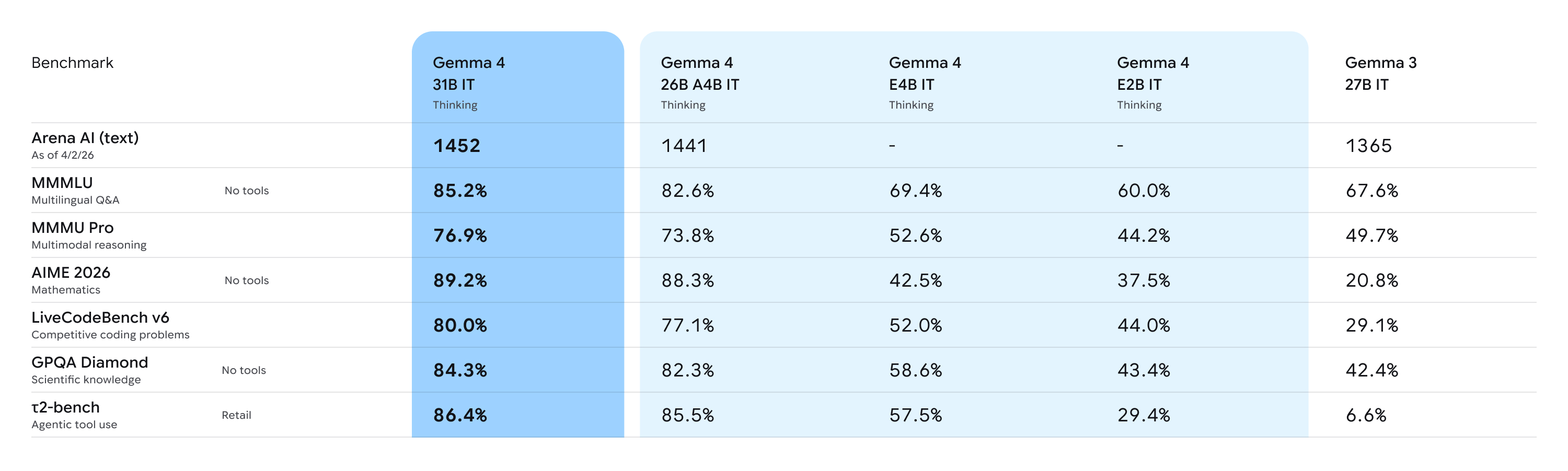
在架构设计上,Gemma 4 展现了极高的灵活性与工程智慧,推出了四种针对不同应用场景的规格:高效的 2B (E2B)、高效的 4B (E4B)、26B 混合专家模型 (MoE) 以及 31B 稠密模型。其性能表现堪称惊艳:31B 模型目前在行业标准的 Arena AI 文本排行榜上稳居全球开源模型第三,26B 模型则位列第六。更令人震撼的是,Gemma 4 在特定任务上的表现甚至能够超越其参数规模大出 20 倍的模型,实现了真正的“以小博大”。
针对开发者对硬件成本与效率的极致追求,Gemma 4 在“单位参数智能”上实现了质的飞跃。E2B 与 E4B 模型专注于重新定义端侧智能的实用性,通过优化多模态能力、降低处理延迟并实现无缝的生态集成,让高性能 AI 能够运行在资源受限的设备上。无论是在全球数十亿台 Android 设备、笔记本电脑 GPU,还是专业级开发者工作站上,开发者都能通过高效的微调,使 Gemma 4 在特定领域达到顶尖水平。目前,我们已见证了其在语言模型开发(如保加利亚语模型 BgGPT)以及生命科学(如耶鲁大学的癌症治疗路径探索)等领域的卓越应用。
在部署效率与生态协同方面,Gemma 4 实现了极致的计算与内存优化。26B MoE 模型通过在推理时仅激活 38 亿个参数,实现了极高的 Token 生成速度;而 31B 稠密模型则专注于追求极致的生成质量。此外,通过与 Google Pixel 团队及高通(Qualcomm)、联发科(MediaTek)等移动硬件巨头的深度协作,这些多模态模型能够在手机、树莓派及 NVIDIA Jetson Orin Nano 等边缘设备上实现近乎零延迟的离线运行。Android 开发者现在即可通过 AICore 开发者预览版,开始构建面向未来的智能代理工作流。
构建 AI 的未来需要协作,而非壁垒。通过发布商业友好的 Apache 2.0 协议,Gemma 4 致力于为开发者提供完整的灵活性与数字主权。我们相信,通过赋能开发者生态,我们将共同推动人工智能迈向更加开放、透明且强大的新高度。
推荐意见